Wer das Refactoring vor das Verstehen setzt, verliert das Mandat, bevor es richtig anfängt. Was in dieser Zeit kommuniziert wird, und was bewusst nicht, entscheidet, ob aus dem Auftrag ein Lead-Mandat über Jahre wird oder ein Sprint-Hopping mit Ablaufdatum. Mein Vorgehen, die Quick Wins, die ich in dieser Zeit tatsächlich ausliefere, und drei Stellen, an denen ich selbst schon falsch abgebogen bin.
Eine konkrete Codebase, die ich vor ein paar Jahren übernommen habe: ein Logistiker, mittlere zweistellige Mitarbeiterzahl, Geschäftsmodell läuft auf einer einzigen PHP-Anwendung. Was ich bei der Übernahme bekommen habe: eine Zip-Datei mit dem Code, einen Zugang zum Live-Server, und eine zweistündige Einweisung vom Vorgänger, der danach raus war. Kein Repository, keine Versionierung, kein Issue-Tracker, keine Doku. Stand des Codes: PHP 5.6, keine Klassenstruktur, kein Autoloader, alles per require und require_once zusammengeklebt. Die Logik verteilt auf viele einzelne Dateien, und in einer guten Hälfte davon echo mit HTML mittendrin. Der Auftrag aus dem Onboarding-Termin, sinngemäß: „Die Anwendung ist zu langsam. In der neuen Version muss sie genauso funktionieren wie bisher.“
Der zweite Satz ist der gefährliche. „Genauso funktionieren wie bisher“ schließt sämtliche Workarounds, Rundungsanomalien und stillen Fixes mit ein, die in den letzten Jahren in den Code gewachsen sind. Niemand schreibt sie auf, niemand denkt aktiv an sie, aber jeder Stammkunde verlässt sich darauf, dass sein spezieller Edge-Case weiterhin so läuft, wie er gestern lief. Wer das überhört und gleich anfängt zu refactorn, bricht das stille Versprechen, das in dieser Auftragszeile drinsteckt. Dann ruft in Monat drei der Buchhalter an und fragt, warum auf einmal alle Frachtbriefe um drei Cent abweichen.
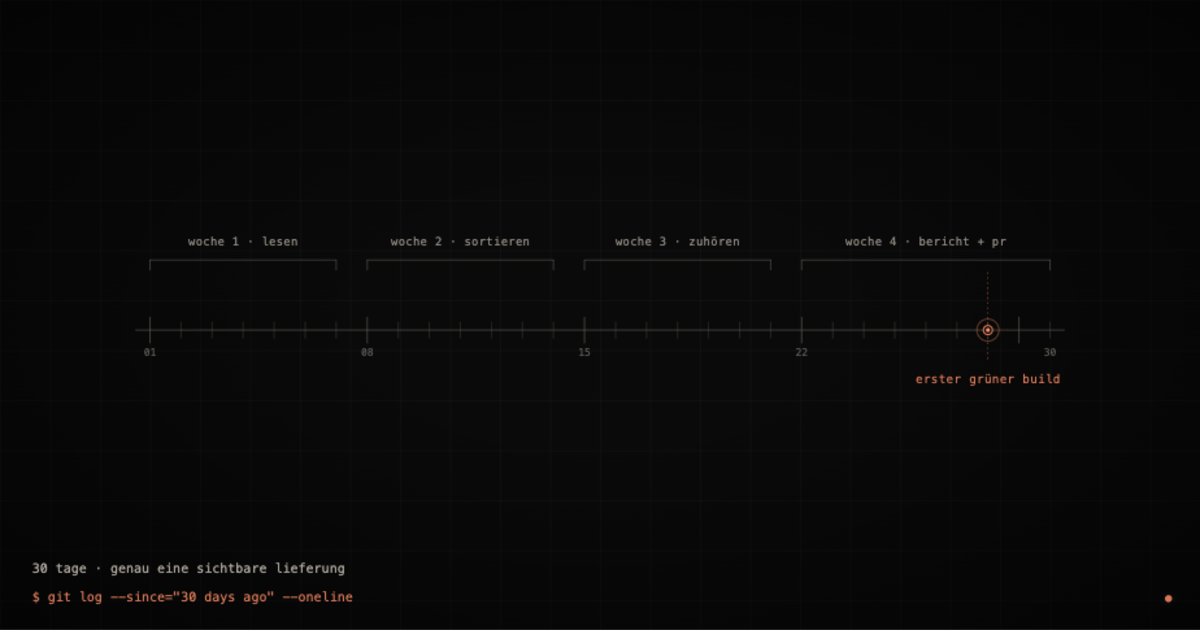
Mein Standard in den ersten 30 Tagen ist deshalb genau eines: nicht alles anfassen. Lesen, sortieren, einen sichtbaren Quick Win ausliefern, der nichts am Verhalten ändert, und am Ende einen Bericht abliefern, den auch jemand versteht, der nie eine Zeile PHP gesehen hat. Klingt nach wenig. Ist aber die Arbeit, die später den Unterschied macht.
Woche 1: Lesen statt Tippen
Was ich anschaue, hängt davon ab, was überhaupt da ist. Wenn es ein Repository gibt, die letzten paar hundert Commits, der Issue-Tracker, die Deployment-Pipeline (falls vorhanden), das Monitoring. Wenn es das alles nicht gibt (wie beim Logistiker), dann lese ich den Code selbst — aber nicht, um ihn zu bewerten, sondern um die fachlichen Hauptpfade zu finden. Welche Datei wird zuerst aufgerufen, wer ruft wen, wo sind die zentralen Datenflüsse. Parallel dazu schreibe ich die Einweisung des Vorgängers mit. Jede Erwähnung eines Kundennamens, eines Sonderfalls, eines „das macht der Cronjob da hinten“ wandert in eine Datei.
Mein Werkzeug in dieser Phase ist schlicht: eine Datei namens notizen.md, die ich vor dem ersten Befehl im Code-Verzeichnis anlege. Da kommt alles rein, was mir auffällt. Sätze aus der Einweisung, Namen, die immer wieder auftauchen, Verzeichnisse, die offensichtlich tote Reste enthalten. Drei Wochen später ist genau dieses File die Rohfassung des Stakeholder-Mappings und der Quick-Win-Liste. Kein Tool, kein Confluence, kein Notion. Eine Datei im Editor, neben dem Code.
Konkret beim Logistiker stand nach Woche 1 schon das Wesentliche fest: kein Repo, kein composer.json, kein Autoloader, kein Weg, modernes PHP, Tests oder DI zu betreiben, ohne diese Schichten zuerst einzuziehen. Damit war eines klar: der erste Quick Win in diesem Mandat würde nicht den Code anfassen, er würde Infrastruktur einziehen. Ohne dass sich am Verhalten der Anwendung eine Zeile ändert.
Woche 2: Hypothesen, keine Fixes
In Woche zwei wird sortiert. Ich baue mir vier Risiko-Kategorien (Sicherheit, Performance, Compliance, Bus-Faktor) und schiebe alles, was bisher in notizen.md gelandet ist, in eine davon. Manchmal in zwei. Nichts wird gefixt. Es wird nur einsortiert.
Wichtig in dieser Woche: echte Quick Wins von solchen unterscheiden, die nur danach aussehen. Eine PHP-Version anzuheben klingt nach Quick Win. Ist es aber nicht, solange keine Tests stehen. Dann ist es eine Wette, die in Monat zwei eine Production-Eskalation produziert. Composer einführen in einer Codebase ohne Klassen dagegen ist ein echter Quick Win. Der Code läuft danach exakt gleich weiter. Die require_once-Ketten kommen schrittweise weg, parallel zur Migration in echte Klassen, aber das ist die Roadmap, nicht der Schritt für Tag eins.
Beim Logistiker waren am Ende von Woche zwei vier Quick-Win-Kandidaten markiert, in zwingender Reihenfolge:
- Repository aufsetzen, vom abgeglichenen Production-Stand (nicht von der Zip — Production ist die Single Source of Truth, weil dort fast immer Hotfixes liegen, die in der Zip fehlen). Git-Init, Initial-Commit,
.gitignorefür Credentials, Caches und User-Uploads. Damit existiert überhaupt erst eine Versionierung, an der die folgenden Schritte hängen können. Vorher gibt es keinen sinnvollen Pull Request, keine CI, kein Rollback. - Composer einziehen,
vendor/autoload.phpin der zentralenindex.phpeinbinden, Classmap-Autoloader auf die bestehenden Verzeichnisse zeigen lassen. Die altenrequires bleiben vorerst drin, der Code-Pfad ändert sich nicht. - CI auf null: ein Workflow, der
composer installmacht und einen statischen Syntax-Lauf über die Codebase. Keine Tests, weil noch keine vorhanden. Aber ab dem ersten Push gilt: rote Pipeline, kein Merge. - Erste Characterization Tests für eine fachlich überschaubare Funktion. Characterization Tests halten das gegenwärtige Verhalten einer Funktion fest, ohne dass ich vorher wissen müsste, was sie soll — sie machen jede ungewollte Verhaltensänderung beim späteren Refactor sichtbar. Beim Logistiker zum Beispiel die Kundenstammdaten-Pflege: einfacher Daten-Fluss, kaum Spezial-Regeln. Bewusst nicht die komplexeste Stelle der Anwendung. Wer am Anfang die kompliziertesten Pfade festschreiben will, scheitert an Sonderregeln, bevor das Werkzeug überhaupt sitzt. Wie ich Characterization Tests technisch aufsetze, steht im letzten Logbuch.
Vier Punkte, die in dieser Reihenfolge gemacht werden müssen. Wer mit Composer anfängt, ohne Repo davor, hat danach lokale Änderungen ohne Geschichte. Wer mit CI anfängt, ohne Composer, prüft eine Konfiguration, die es noch nicht gibt.
Woche 3: Wer das System braucht, wer es bezahlt, wer es blockieren kann
In gewachsenen Mittelstandsbuden gibt es selten ein sauberes Org-Chart. Beim Logistiker waren es im Kern drei Gruppen, mit denen ich klarkommen musste: der Ops-Leiter, der jeden Tag mit der Anwendung arbeitet und dessen ganzes Geschäft davon abhängt; der Chef, der die Übernahme bezahlt und entscheidet, was als „in Ordnung“ durchgeht; und eine Handvoll Mitarbeiter aus Disposition, Buchhaltung und Vertrieb, jede mit einer eigenen Liste von Wünschen, Sonderfällen und genervten Beschwerden.
Was ich in dieser Woche mache, ist nicht „Stakeholder-Mapping“ im Berater-Sinne, sondern aktives Zuhören. Einen halben Tag beim Ops-Leiter dabei sitzen und beim echten Tagesgeschäft zuschauen — das ist der Punkt, an dem ich überhaupt verstehe, was die Anwendung tatsächlich tut, wo die Reibung sitzt und welche Workarounds die Leute über die Jahre eingespielt haben. Den Chef ein zweites Mal treffen und nachhaken, was er konkret mit „zu langsam“ meint — oft ist es etwas anderes als das, was beim ersten Termin gesagt wurde. Und mit den Mitarbeitern reden. Aber dabei eine Regel beachten: Beschwerden ernster nehmen als Wünsche. Wünsche sind Wunschdenken. Beschwerden kommen aus der täglichen Arbeit und sind die ehrlichste Quelle, die ich in dieser Phase überhaupt finde.
Was ich in dieser Woche bewusst noch nicht mache: alles in einen Backlog kippen. Das wäre zu früh. In Woche 3 wird gesammelt und gewichtet, in Woche 4 fließt das in den Bericht. Ein Backlog entsteht erst danach, sobald über die ersten Maßnahmen entschieden ist. Sonst sortiere ich Symptome, bevor ich die Ursachen verstanden habe.
Eine Frage hilft in dieser Phase besonders, ich stelle sie offen: „Wenn ich an dieser Stelle etwas ändern wollte, wen müsste ich vorher fragen, damit es in zwei Monaten nicht zurückgedreht wird?“ Die Antworten sind selten die, die in einer formalen Hierarchie ganz oben stehen.
Woche 4: Der Bericht, plus der erste PR
In Woche vier kommt beides. Der Bericht für die Stakeholder und der erste sichtbare Schritt im Repo. Beides parallel, damit der Bericht nicht reine Analyse bleibt.
Der Bericht
Zwei Seiten. Drei Sektionen. Keine PowerPoint.
Sektion 1: Was ist. Nüchterner Zustand. Keine Wertung, keine Schuldzuweisung. Was läuft, was nicht, was steht ungetestet auf Produktion. Beim Logistiker stand in dieser Sektion zum Beispiel:
- Keine Versionskontrolle. Quellstand ist eine Zip-Datei plus die Inhalte des Live-Servers; die einzige verlässliche Historie sitzt im Kopf des bisherigen Entwicklers.
- PHP-Version 5.6, EOL seit Januar 2019. Sprung auf 7.4 blockiert durch direkt verwendete
mysql_*-Funktionen (in 7.0 entfernt) und mehrere fest einkopierte Helper-Bibliotheken aus der 5.x-Zeit. Composer-Dependencies gibt es nicht; die Blocker sitzen alle direkt im Projekt-Code und müssen einzeln angefasst werden. - Kein Composer-Setup, kein Autoloader. Klassen-Migration ist Voraussetzung für Tests, DI, statische Analyse.
- Keine CI. Deployments per FTP vom Entwickler-Laptop. „Grün“ heißt: läuft auf meinem Rechner.
Konkrete Daten, konkrete Folgen, keine Adjektive. Wer hier „viele“, „zahlreich“ oder „kritisch“ schreibt, ist nicht im Modus Beobachtung, sondern im Modus Verkauf.
Sektion 2: Was ich vorschlage. Drei bis fünf Maßnahmen, jede mit Aufwand-Größenordnung und Effekt. Wichtig: nur Maßnahme eins liegt innerhalb der ersten 30 Tage, alles andere markiere ich explizit als Folge-Maßnahme. Beim Logistiker war Maßnahme eins die Infrastruktur in der Reihenfolge Repo, Composer, CI; Maßnahme zwei (als erste Folge-Maßnahme im nächsten Quartal) das Auslagern der Kundenstammdaten-Pflege in eine eigene Klasse, mit Tests, als erste echte Übung im neuen Setup; Maßnahme drei (im Quartal danach) das Upgrade auf PHP 7.4 nach erfolgter Testabdeckung der hauptsächlichen Pfade. Die komplexeren Stellen der Anwendung kommen erst danach, in eigenen Maßnahmen über mehrere Quartale gestreckt, nicht in einem Sprint.
Sektion 3: Was ich nicht vorschlage und warum. Die wichtigste Sektion. Hier steht, was nicht angefasst wird, obwohl es danach aussieht. Beim Logistiker standen in dieser Sektion drei Punkte:
- Kein Direkt-Sprung von PHP 5.6 auf 8.x. Begründung: Breaking Changes über drei Major-Versionen, ohne Test-Abdeckung wäre das eine Wette, keine Migration. Pfad ist 5.6 → 7.4 → 8.2 als eigenständige Quartals-Maßnahmen nach den ersten 30 Tagen, mit Test-Stabilisierung zwischen den Schritten.
- Keine Trennung von HTML-Ausgabe und PHP-Logik im großen Stil. Begründung: jeder Schritt verändert das gerenderte Markup; ohne Snapshot- oder End-to-End-Tests sind visuelle Regressionen (kaputte Layouts, fehlende CSS-Klassen in Edge-Cases) automatisiert praktisch nicht zu fangen. Gehört in eine eigene Quartals-Maßnahme nach Test- und CI-Stabilisierung, nicht in die ersten Monate.
- Kein Einzug einer ORM (Doctrine oder Eloquent) zum jetzigen Zeitpunkt. Begründung: der DB-Layer mit
mysql_*ist hässlich, aber funktional; ORM-Einführung wäre eine Antwort auf ein Problem, das in dieser Anwendung nicht das größte ist. Erst nach der Migration auf PHP 7.x und einem belastbaren Klassen-Schnitt überhaupt relevant — Quartale später, nicht in den ersten 30 Tagen.
Drei Sätze pro Punkt, keine Drohung, kein Marketing. Genau das ist die Sektion, an der CTOs aufhören zu skimmen und anfangen zu lesen.
Der erste Schritt im Repo
Der Quick Win, der den Bericht in Woche vier konkret macht, läuft beim Logistiker in zwei Phasen, die strikt in dieser Reihenfolge passieren müssen.
Zuerst der Abgleich zwischen Zip-Stand und Live-Server. Bei jeder Übernahme, die ich bislang gemacht habe, gab es da Unterschiede. Hotfixes, die in den letzten Wochen oder Monaten direkt am Server eingespielt wurden und nie zurück in den „offiziellen“ Stand geflossen sind. Mal eine veränderte Konfig, mal eine eilig gepatchte Funktion, mal eine ganze Datei, die in der Zip schlicht fehlt. Production ist die Single Source of Truth. Also nehme ich den Production-Stand als Basis, vergleiche ihn mit der Zip (jede Differenz wandert in notizen.md, mit kurzer Vermutung warum) und committe den Production-Stand als Initial-Commit, mit .gitignore für Credentials, Caches und User-Uploads.
Sobald dieser Commit auf einer privaten Origin liegt, kommt der eigentliche erste Pull Request: Composer rein, CI grün.
Composer-Setup minimal:
{
"name": "kunde/anwendung",
"type": "project",
"require": {
"php": ">=5.6"
},
"autoload": {
"classmap": ["src/", "lib/", "includes/"]
},
"config": {
"sort-packages": true
}
}Classmap auf die bestehenden Verzeichnisse, sonst nichts. Klassen, die noch nicht existieren, müssen auch nicht namespaced sein, der Autoloader findet sie trotzdem, sobald sie als Klassen vorliegen. In einem zentralen Bootstrap oder in der index.php wird vendor/autoload.php einmal eingebunden. Die alten requires bleiben vorerst drin und werden Stück für Stück entfernt, sobald die jeweiligen Dateien in echte Klassen migriert sind. Kein Big Bang, keine Verhaltensänderung an Tag eins.
Dazu die erste CI:
name: CI
on: [push, pull_request]
jobs:
build:
runs-on: ubuntu-20.04 # noch supportet fuer PHP 5.6 zur Uebernahmezeit
steps:
- uses: actions/checkout@v4
- uses: shivammathur/setup-php@v2
with:
php-version: '5.6'
coverage: none
- run: composer install --no-dev --prefer-dist --no-interaction
- name: PHP-Lint
run: find . -type f -name '*.php' -not -path './vendor/*' -print0 | xargs -0 -n1 php -lDrei Anmerkungen zu diesem Diff, weil der Reflex zum Aufpolieren sonst zu groß ist.
Wichtig zur zeitlichen Einordnung: das gezeigte YAML ist ein historisches Praxisbeispiel aus der echten Übernahme. So lief das Setup damals. Heute, im Jahr 2026, ist die Kombination shivammathur/setup-php + PHP 5.6 auf modernen Runnern (ubuntu-22.04 und neuer) faktisch tot, weil die zugrundeliegenden ondrej/php-Repositories für aktuelle Ubuntu-Versionen keine 5.6-Pakete mehr ausliefern. Ich ändere die Version im Beispiel hier trotzdem nicht auf 7.4, nur damit das YAML 2026-tauglich aussieht. Das würde meinen eigenen Ansatz verwässern: wenn Production auf 5.6 läuft, läuft die CI auf 5.6. Punkt. In aktuellen Pipelines verpacke ich den ganzen Step pragmatisch in einen php:5.6-cli-Docker-Container und lasse den auf einem aktuellen Runner laufen. Effekt identisch: 5.6-Lint auf 5.6-Laufzeit, ohne dass die Anwendung dafür einen Versionssprung mitmachen muss.
composer install --no-dev ist hier vor allem dazu da, den Autoloader zu generieren und sicherzustellen, dass die composer.json valide ist. --no-dev hält den Build schlank, mehr nicht. Sobald Tests dazukommen (PHPUnit, PHPStan), bekommt die Test-Stufe einen eigenen Step ohne --no-dev, weil sie die dev-Dependencies braucht. In dieser nullten Stufe gibt es noch keine, das --no-dev ist also strenggenommen folgenlos — es markiert nur die Konvention für später.
php -l über jede Datei ist alles, was hier sinnvoll an statischer Analyse läuft. PHPStan und PHPUnit kommen erst in der nächsten Iteration dazu, sobald die Migration auf 7.4 in der Anwendung durch ist und die ersten Characterization Tests geschrieben sind. In dieser nullten Stufe geht es nicht um Code-Qualität, sondern darum, dass ab dem nächsten Push überhaupt eine Pipeline existiert, die rot werden kann.
Initial-Commit plus diese beiden Diffs zusammen, also composer.json plus .github/workflows/ci.yml, sind unter zwanzig Zeilen neuer Code. Sie ändern null Verhalten am Produkt-Code, und genau das ist der Punkt. Ab dem Moment, in dem der PR durchgeht, gilt: jeder weitere Push muss durch die Pipeline, und jede Änderung hat einen Autor, ein Datum und einen Diff. Ab da kann die eigentliche Modernisierung anfangen — aber als eigenständige Maßnahmen nach den ersten 30 Tagen, jede in einem eigenen Quartal: schrittweises Auslagern in Klassen, DI für die ausgelagerten Teile, Tests pro neuer Methode, später das Upgrade auf 7.4, am Ende Route-für-Route nach Strangler-Fig in Richtung 8.2.
Der erste grüne Build ist psychologisch wichtiger als der hundertste perfekte. Damit ist im Bericht in Sektion 2 ein Punkt belegt, nicht nur behauptet. Das Mandat hat seine erste Lieferung, und niemand muss Angst haben, dass etwas Sichtbares an der Software gebrochen ist.
Stolperfallen
Drei Stellen, an denen ich selbst schon falsch abgebogen bin oder die ich regelmäßig sehe.
Der erste Eingriff am Live-Server. Bei Übernahmen wie der oben beschriebenen hat man sofort Live-Zugang, aber noch kein Repo. Gleichzeitig brennt irgendwo immer etwas — eine Beschwerde, ein langsamer Cronjob, ein Bug, den der Ops-Leiter beim halben Tag Mitsitzen zeigt. Die Versuchung, „mal kurz“ am Live-Code zu fixen, ist real. Wer das tut, hat den Initial-Commit kaputtgemacht, bevor er überhaupt existiert. Zwischen Zip-Stand und Repo-Stand driftet der Code, und die Geschichte fehlt für immer. Meine Regel: bis das Repo steht, läuft am Live-Code nichts. Auch dann nicht, wenn jemand sagt, das wäre doch nur eine Zeile.
Der informelle Entscheider, den man übersieht. Habe ich oben schon angedeutet. Wer die Person aus dem Fachbereich übersieht, die seit Jahren die Workarounds kennt und über jede Änderung in der Stille mitstimmt, schreibt einen Bericht, dem in der Bewertungsrunde leise das Wasser abgegraben wird, ohne dass je offen widersprochen wird.
Im Bericht stark klingen statt ehrlich. In Sektion 1 „kritisch“ schreiben, wo „mysql_*-Aufrufe an mehreren Stellen, blockieren das Upgrade auf 7.0″ gereicht hätte. Wer Risiken aufbläst, hat in Monat vier ein Problem, weil die Maßnahmen das Aufgeblähte nie ganz einlösen. Wer Risiken kleinredet, hat in Monat vier auch ein Problem, weil dann das Erste, was eskaliert, als Überraschung ankommt. Die ehrliche Größenordnung ist die unsexyste Variante. Und die einzige, die das Mandat hält.
Wenn Sie gerade vor einer Übernahme stehen oder eine planen: schicken Sie mir kurz Ihre Ausgangslage. Ich melde mich mit einer ersten Einschätzung zurück, was ich an Ihrer Stelle in den ersten 30 Tagen anpacken würde und was bewusst nicht. Termin buchen.